一. 預訓練的BERT
接下來會介紹hugging face這個團隊提供的BERT的套件來做介紹~BERT的model本質本來就是預訓練模型。今天主要介紹 Bert 預訓練模型的使用方法。
如下圖,此圖來自Coupy的'NLP 100天馬拉松'的圖,網路上有人利用BERT將句子轉成編碼,再經過自己設計好的分類器,如羅吉斯回歸、LSTM都可以唷~~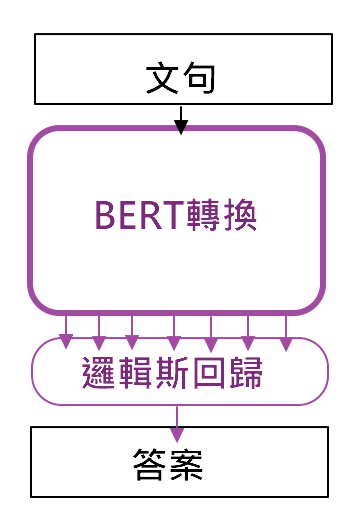
二. 程式實現
接下來我們載入google 的 BERT,並利用他來轉換成句子的編碼
import numpy as np
import pandas as pd
import torch
import transformers as ppb # pytorch transformers
configuration = ppb.BertConfig()
configuration
輸出後如下圖:
def tokenize(text):
text = re.sub('[^\u4e00-\u9fa5A-Za-z0-9]','',text)
return text
text = '為什麼聖結石會被酸而這群人不會'
train_text = tokenize(text)
# 載入 Bert 模型
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel(configuration), ppb.BertTokenizer, 'bert-base-chinese')
# 載入預訓練權重以及 tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
max_len = 32
train_text = tokenizer.encode(train_text, add_special_tokens=True, max_length=max_len, truncation=True, padding=True)
train_text
輸出後如下圖:
padded = np.array([train_text + [0]*(max_len-len(train_text))])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.tensor(padded).to(torch.int64)
attention_mask = torch.tensor(attention_mask).to(torch.int64)
with torch.no_grad():
last_hidden_states = model(input_ids, attention_mask=attention_mask)
last_hidden_states.pooler_output
output,編碼為768維度的向量: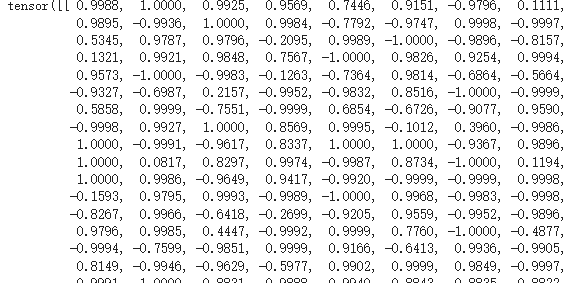
bert其實對於句子的編碼語意理解那邊是不太好,滿多人推薦SBERT這個方法,有興趣可以查一下唷~~

